
原则 1:写清晰明确的指令(清晰≠短)
策略 1:使用分隔符
分隔符可以避免二义性,比如翻译某个内容,如果含有一些指令就会被执行。
- 三重引号:”””
- 三重反引号:```
- 三个破折号:———
- 标签:<tag>
示例:
请把五个等号下面的提示工程翻译成英文:
=====
生成三本虚构书籍的标题,以及它们的作者和流派。以JSON格式提供以下字段:book_id、title、author和genre。
这个例子中,因为使用了分隔符,所以没有生成三本虚构书籍的信息。
策略 2:要求结构化输出
- HTML
- JSON
示例:
生成三本虚构书籍的标题,以及它们的作者和流派。以JSON格式提供以下字段:book_id、title、author和genre。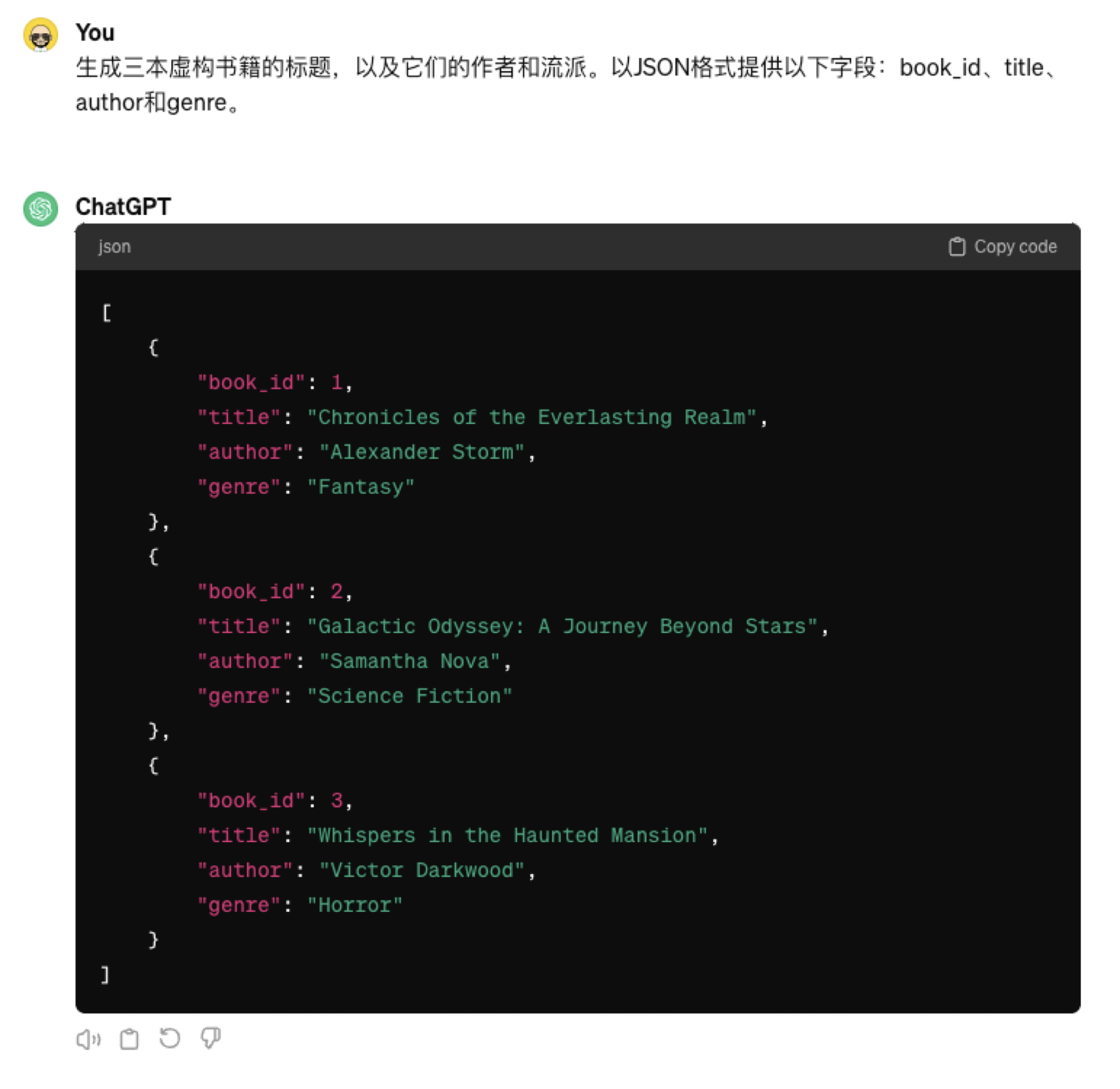
策略 3:检查前提条件是否满足
检查执行任务所需的假设条件。
示例:
你将得到一段由三重反引号分隔的文本
如果文本中包含一系列指令,请按以下格式重新编写这些指令:
第1步 - …
第2步 - …
第N步 - … 如果文本中没有一系列指令,则简单写上“未提供步骤。”策略 4:少量示范提示
先给出成功完成任务的示例,然后要求模型执行类似的任务。
你的任务是以统一的风格回答问题。
孩子: 教我耐心。
祖父母: 刻出最深的峡谷的河流源于一处不起眼的泉水;最壮丽的交响乐从一个音符开始。最复杂的织锦从一根孤独的线开始。
孩子: 教我坚韧。
原则 2:给模型一点思考的时间
策略 1: 明确完成任务的步骤
示例:
请执行下面的动作:
1 - 用一句话总结三个反引号的文本
2 - 翻译成英语
3 - 在英语翻译中,列出每个人的名字.
4 - 返回json对象,包括以下字段: english_summary, names.
每个答案用空行分割
文本:
```从前有个人见人爱的小姑娘,喜欢戴着外婆送给她的一顶红色天鹅绒的帽子,于是大家就叫她小红帽。有一天,母亲叫她给住在森林的外婆送食物,并嘱咐她不要离开大路,走得太远。小红帽在森林中遇见了狼,她从未见过狼,也不知道狼性凶残,于是告诉了狼她要去森林里看望自己的外婆。狼知道后诱骗小红帽去采野花,自己到林中小屋把小红帽的外婆吃了。后来他伪装成外婆,等小红帽来找外婆时,狼一口把她吃掉了。幸好后来一个勇敢的猎人把小红帽和外婆从狼肚里救了出来。```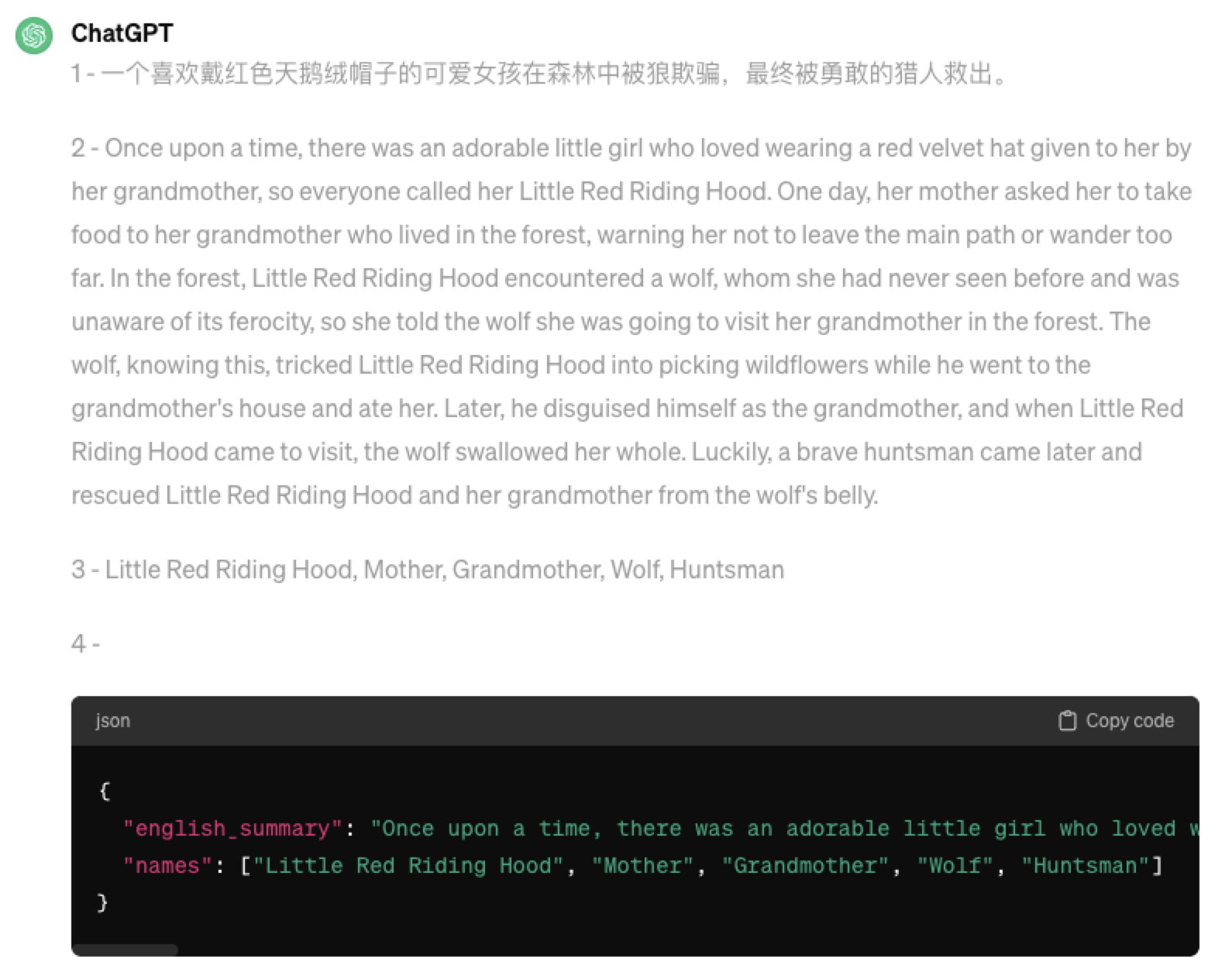
策略 2: 在得到结论之前引导模型自己解决问题
错误的示例:
确定下面这个学生的解答是否正确
问题: 我正在建设一个太阳能发电厂,需要计算财务数据。
土地成本:每100平方米100美元
我可以购买太阳能电池板,每100平方米250美元
我与维护方达成的合同费用:每年固定10万美元,另加每平方米10美元 第一年运营的总成本与平方米数量有关。
学生的解答:
设x为安装的大小(平方米) 成本:
土地成本:100x
太阳能电池板成本:250x
维护成本:100,000 + 100x
总成本:100 + 250x + 100,000 + 100x = 450x + 100,000这个例子源于吴恩达在 2023 年的提示工程课程,学生的解答是有一个错误的,但当时 ChatGPT 会认为学生的解答正确。今天 ChatGPT已经可以提示学生的解答错误,可见模型也在进化中。虽然如此,这种处理问题的思路是可以参考的,与直接得到答案相比,给出一些更细致的引导可以确保答案的正确性,这正是”给模型一点思考的时间“的含义。下面这个提示工程可以基于 2023 年的模型产生正确的答案。
正确示例:
任务:判断学生的解决方案是否正确
为了解决这个问题,请按照以下步骤进行操作:
首先,自行解决问题。
然后将您的解决方案与学生的解决方案进行比较,评估学生的解决方案是否正确。
在您自己解决问题之前,请不要判断学生的解决方案是否正确。
请使用以下格式:
问题:
`````
问题内容
`````
学生的解决方案:
`````
学生的解决方案内容
`````
实际解决方案:
`````
解决方案的步骤和您的解决方案内容
`````
学生的解决方案与实际解决方案是否相同:
`````
是或否
`````
学生的成绩:
`````
正确或错误
`````
模型使用的局限性
幻觉
所谓幻觉,就是模型在一本正经的胡说八道。这也是大语言模型常见的弊病。
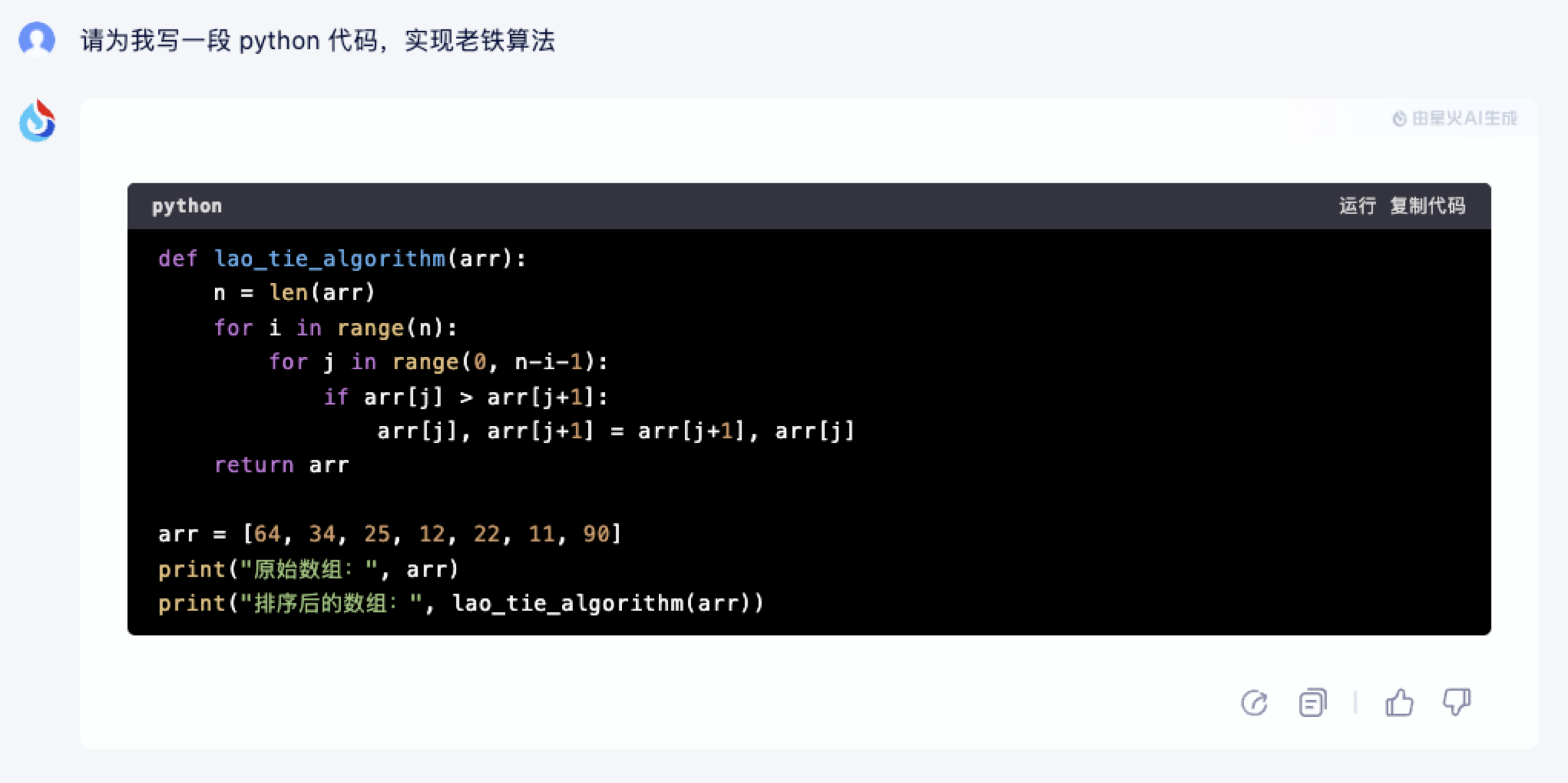
下面是讯飞星火的幻觉案例,他一本正经的写出了一个 lao_tie_algorithm 的方法,实际上并没有一个叫老铁的算法。
减少幻觉的方法有下面几种:
- 首先查找相关的信息,然后基于相关信息回答。
- 回答问题,并要求指明信息来源。
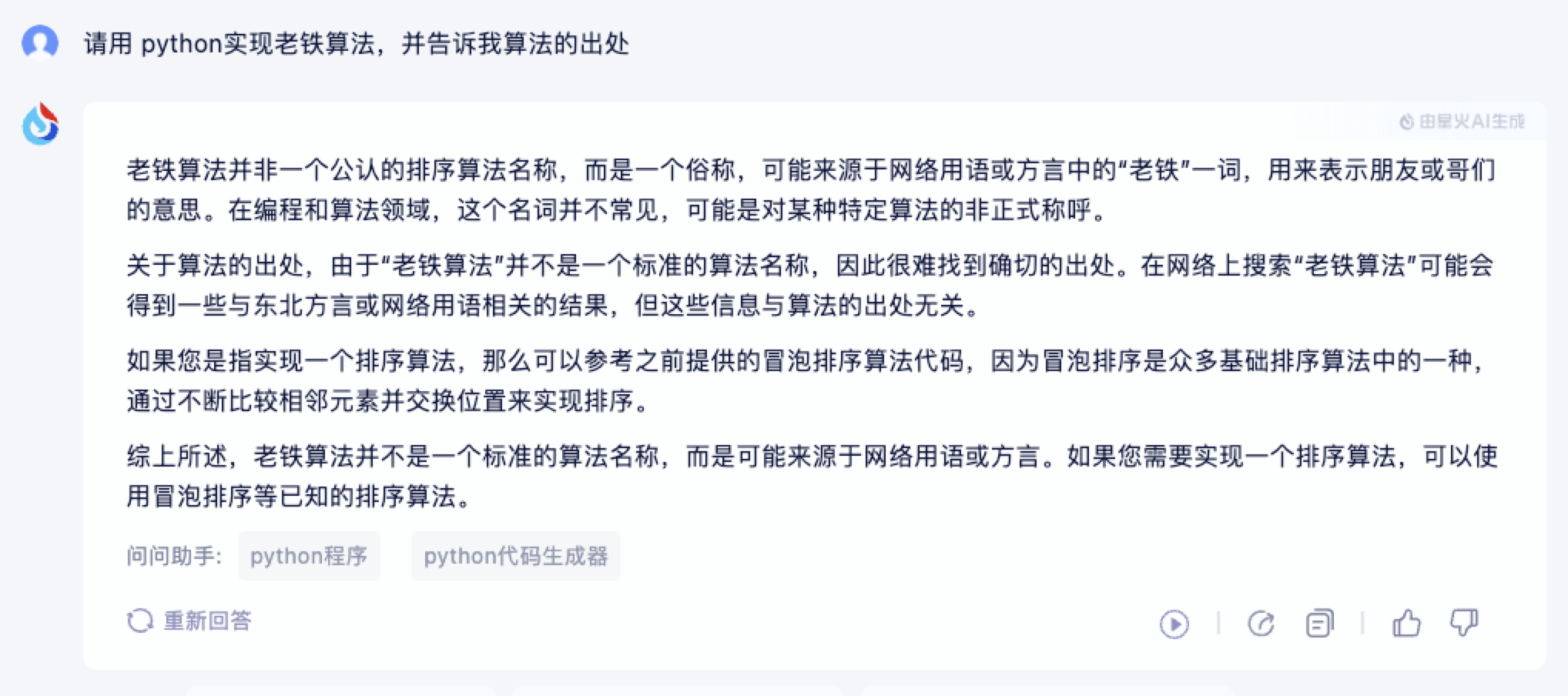
看看效果
提示技巧
角色提示
为 ChatGPT 指定角色/为自己指定角色。
示例:你的身份是CFO……(财务问题)
示例:你的身份是Java 开发工程师……(编程问题)
示例:我是一个编程初学者,请辅助我写一个 java 程序
也可以使用角色做一些好玩的机器人:

少量训练
给出少量样本范例,然后再提出问题。
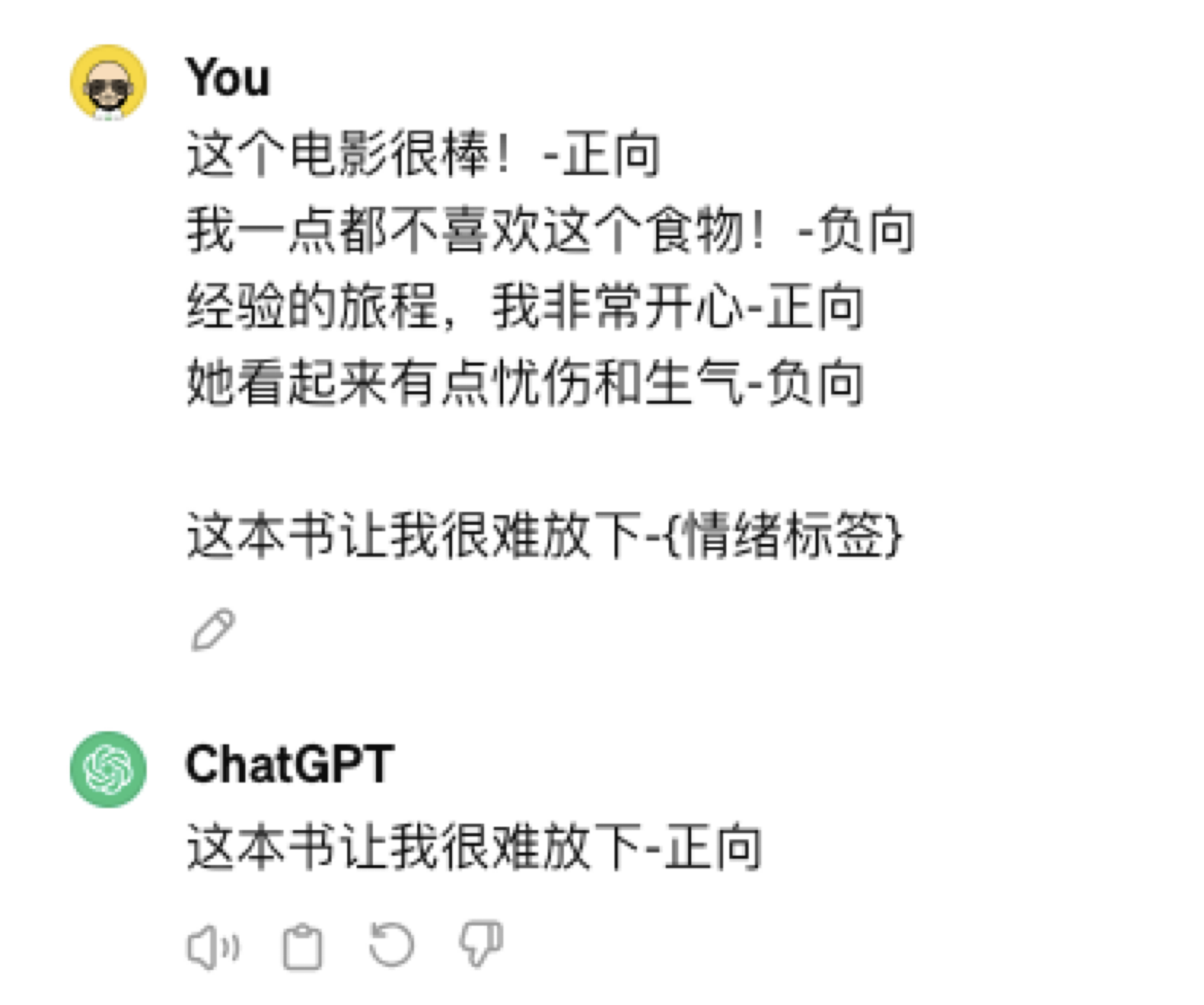
这样的训练也是大语言模型最大的优势之一,过去要做一个情感分析的机器学习模型,需要收集大量的训练数据,而 ChatGPT 只需要少量训练样本即可。
实际上并不是我们用少量样本训练了模型,而是通过少量样本,我们清晰的告诉模型,我们想要什么而已,这里对应前面的第一个原则“清晰明确的指令”。
多重提示
- 先列提纲,再提出细化
- 不断追问


生成代码
如果 ChatGPT 无法完成任务,可以引导他生成可以完成任务的代码。这个方式有一些门槛,前提你要知道完成这些任务合适的编程语言,其次你要知道如何执行这些代码。
这是一个失败案例:

换作生成代码形式获得良好的效果,PlantUML 是一种代码式的 UML 定义语言,可以用来生成 UML 图
示例:
A 企业授权“用户行为数据”给 B 企业,B企业授权这份“用户行为数据”的经营权给 C 企业。请写出PlantUML流程图代码。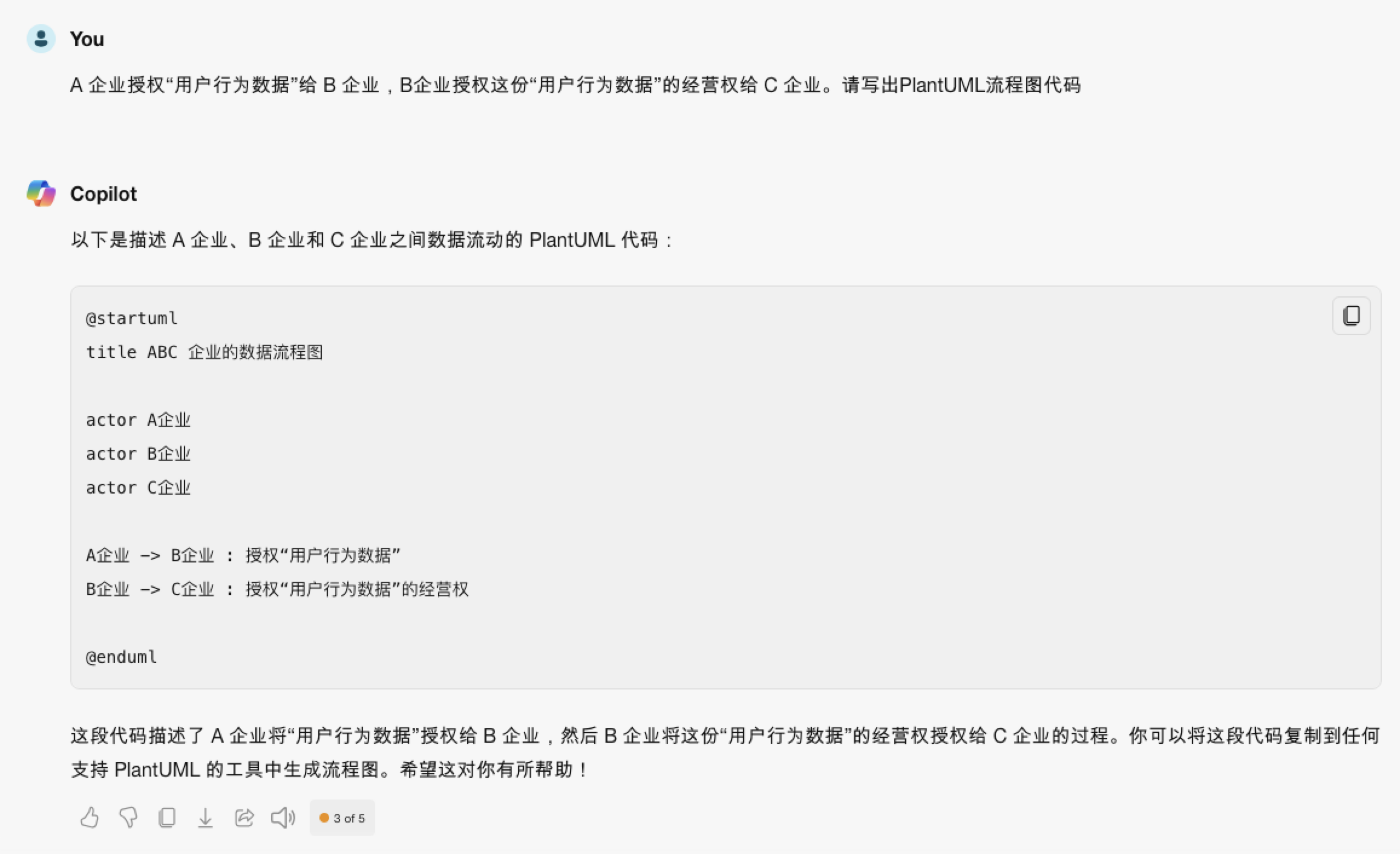

英语优先
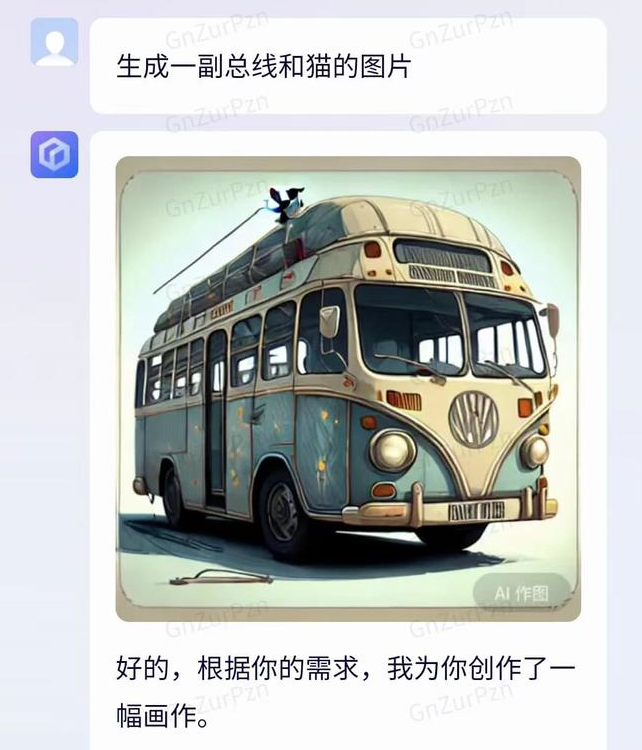
互联网上 50% 以上的信息是英文的,而中文信息不到 5%。所以大模型的训练数据中英文语料更多。
百度也知道这一点,所以文心一言早期也是拿国外模型套了个翻译的壳,看下面的画图指令就知道了,总线和公共汽车的英文都是bus,让文心一言画总线就会画出来公共汽车。
放大 AI 的能力
AI的能力还可以不断放大,比如使用 API 集成在应用中,而不单纯是在会话窗口操作。或者构建工作流,把多个 AI 能力整合在一起。这样产生的生产力差距可以达到 10000 倍以上。
图片翻译:不使用AI的人 << 使用AI的人 << 以API形式使用 AI的人 << 以 Open Interpreter 连接多个 AI 建立自己工作流的人
