
chunk在计算机行业通常表示数据块。数据库查询下也有一个chunk方法,依据函数式编程思想设计。第一个参数是chunk大小,第二个参数是一个callable。
使用方法如下:
DB::table('users')->orderBy('id')->chunk(100, function ($users) {
foreach ($users as $user) {
//
}
});
它的实现方式其实不高深但是用于批量传输数据的时候非常实用。代码实现在Illuminate\Database\Concerns\BuildsQueries (Laravel 5.4)。copy如下:
/**
* Chunk the results of the query.
*
* @param int $count
* @param callable $callback
* @return bool
*/
public function chunk($count, callable $callback)
{
$this->enforceOrderBy();
$page = 1;
do {
// We'll execute the query for the given page and get the results. If there are
// no results we can just break and return from here. When there are results
// we will call the callback with the current chunk of these results here.
$results = $this->forPage($page, $count)->get();
$countResults = $results->count();
if ($countResults == 0) {
break;
}
// On each chunk result set, we will pass them to the callback and then let the
// developer take care of everything within the callback, which allows us to
// keep the memory low for spinning through large result sets for working.
if ($callback($results) === false) {
return false;
}
$page++;
} while ($countResults == $count);
return true;
}
可以看到其实就是一个分页查询。因此它也具备分页查询的缺点:在超长列表下查询性能差。比如100w的列表,查询到后面会出现Limit 990000, 100这样的分页查询,对于超大的偏移量,MySQL的处理是从头扫描!!!因此,分页越往后单个查询耗时越多。
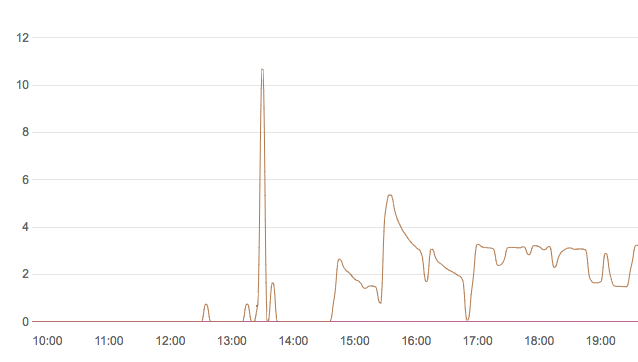
上图是一个数据库QPS(每秒查询数)记录,15:00~17:00有三段下坡的曲线就是执行上面代码产生的(三次运行,使用不同limit,所以基数不同),充分阐释了offset带来的性能问题。每一次执行之初具有极快的返回时间,所以每秒可以发送更多的请求。随着offset增大,每次查询耗时越来越多,导致每秒可返回的查询数不断减少。
这种情况可以结合实际情况对查询条件进行优化,因为上面查询是主键扫描,所以可以用主键做分段条件,类似上面那个查询我是这样做的:
$start;//起始ID
$end;//终止ID
$intervalLen = 10000; //区间长度,SQL的最大offset
$intervalL = $start; //左区间
do{
$intervalR = min($intervalL + $intervalLen, $end); //右区间
DB::table('users')
->where('id', '>=', $intervalL)
->where('id', '<', $intervalR)
->orderBy('id', 'ASC')
->chunk(200, function($records) use ($otsClient){
$put_rows = [];
foreach ($records as $record) {
......
}
});
$intervalL = $intervalR;
}while($intervalL < $end);
因为这个查询是根据id升序排序查询,所以将超长列表根据id再分区间。避免过大的offset。而条件中的id因为是主键,所以可以利用索引快速定位。因此可以一定程度上提高效率。上图17:00之后的统计曲线就是优化之后的代码产生的,可以看到已经没有了衰减的趋势(个别位置凹下去是因为跑完了$start~$end的所有数据,手动重启的间隙)。
总结一下,这种批量处理数据避免过大的offset是性能提升的关键,其次在内存、写入等条件允许的情况下提高limit也有一定好处。其实上面例子中区间长度如果与chunk相等是最优效果。可是这样的话有什么好chunk呢![]()