
前言
MySQL其实很早就支持了全文索引,5.6版本之前只有MyISAM引擎支持,5.6及以后版本InnoDB也支持了。但是在中国的开发圈里面似乎绝少人使用。其原因无外乎MySQL全文索引对中文支持并不友好,而不友好的关键就在于没有中文分词器。对英文以及同类拼音文字来说,采用空格和停止词即可搞定所有场景了。而中文的单词总是粘成一块,甚至在一百年前连标点符号都没有。
但是,MySQL居然内置了日文分词器MeCab,这甚至是唯一针对某一语言的分词器,向工匠精神的日文开发者致敬。
全文索引技术简介
全文索引主要解决在大段文本中查找关键词的问题(全文搜索),SQL传统的LIKE方法采用模糊匹配算法,假设字段的字符串平均长度是M,数据库中有N条记录,在无法使用索引的情况下,时间复杂度是O(M*N)。
全文索引技术通常采用了倒排索引技术,简单来说就是先把大段的文本拆成一个个单词,然后针对单词创建索引,单词对应到数据行的ID,这样快速找到单词即可快速定位到数据的位置。而倒排索引的时间复杂度可以达到O(1),而其余的性能影响因素,就只取决于倒排索引召回的记录数了,这个数字通常很小。
下面是 elasticsearch 内核Lucene的倒排索引示意图
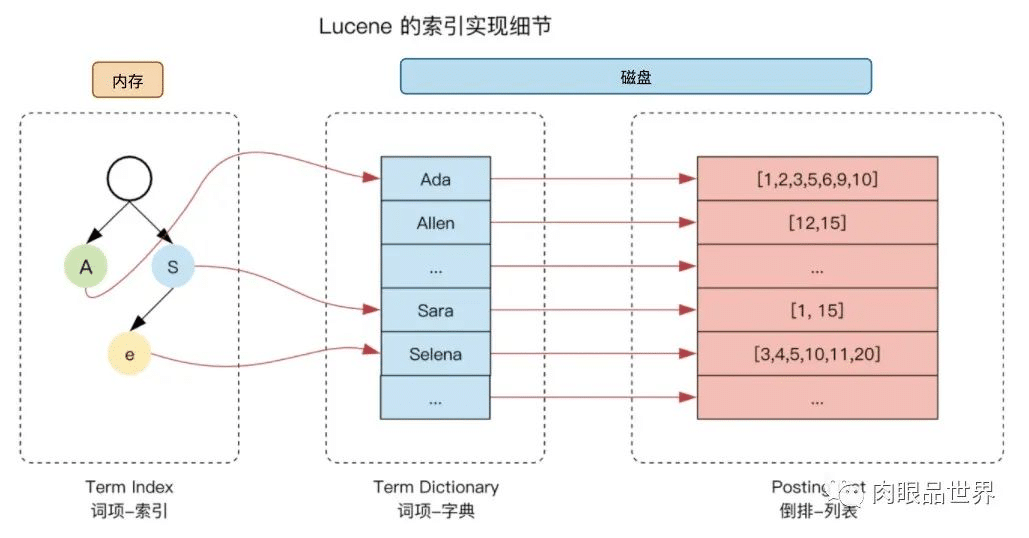
举例说明,下面是三条要被索引的文本:
- T0
= "it is what it is" T1 = "what is it"T2 = "it is a banana"
我们就能得到下面的倒排索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}每个单词后面的集合对应的是文本的ID。
MySQL全文索引实验
数据准备
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title),
FULLTEXT (body) with parser ngram
) ENGINE=InnoDB;
insert into benchmark.articles (id, title, body)
values (1, 'MySQL Tutorial', 'MySQL Tutorial'),
(2, 'How To Use MySQL', 'How To Use MySQL'),
(3, 'Optimizing Your Database', 'Optimizing Your Database'),
(4, 'MySQL vs. YourSQL', 'MySQL vs. YourSQL'),
(5, 'MySQL Security', 'MySQL Security'),
(6, 'Database, Database, Database', 'Database, Database, Database'),
(7, '1001 MySQL Tricks', '1001 MySQL Tricks'),
(8, 'MySQL Full-Text Indexes', 'MySQL Full-Text Indexes'),
(9, 'indexdata full tokenized', 'indexdata full tokenized'),
(10, '钟薛高及其创始人林盛被限消', '钟薛高及其创始人林盛被限消'),
(11, '钟薛高 及其 创始人 林盛 被 限消', '钟薛高 及其 创始人 林盛 被 限消');
这个例子,我们创建了一个article表,并对title和body创建了两个全文索引,这两个索引的原理略有不同,稍后我们分析。
SQL测试
我们执行下面的语句看看结果。
SELECT id, title, body,
MATCH (title) AGAINST ('database' IN BOOLEAN MODE) AS score
FROM articles ORDER BY score DESC;
| id | title | body | score |
|---|---|---|---|
| 6 | Database, Database, Database | Database, Database, Database | 1.6444 |
| 3 | Optimizing Your Database | Optimizing Your Database | 0.5481 |
| 1 | MySQL Tutorial | MySQL Tutorial | 0 |
| 2 | How To Use MySQL | How To Use MySQL | 0 |
| ... |
这个MATCH语句也可以放在where条件里面直接做筛选,我们放在SELECT中可以看到这个方法对所有记录的score。根据TF-IDF的原理,次频更高的具有更高的得分,id=6的这条记录中出现了3次database,id=3的记录只出现了1次database,因此id=6的得分恰好是id=3的三倍。
上面是输入一个完整词条的搜索结果,我们试试搜索data
SELECT id, title, body,
MATCH (title) AGAINST ('data' IN BOOLEAN MODE) AS score
FROM articles ORDER BY score DESC;
| id | title | body | score |
|---|---|---|---|
| 1 | MySQL Tutorial | MySQL Tutorial | 0 |
| 2 | How To Use MySQL | How To Use MySQL | 0 |
| ... | |||
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 0 |
我们发现所有的得分都是0,也就是没有命中结果,我们试试下面两种形式。
-- 前缀匹配模式
SELECT id, title, body,
MATCH (title) AGAINST ('data*' IN BOOLEAN MODE) AS score
FROM articles ORDER BY score DESC;
| id | title | body | score |
|---|---|---|---|
| 6 | Database, Database, Database | Database, Database, Database | 1.6444 |
| 3 | Optimizing Your Database | Optimizing Your Database | 0.5481 |
| 1 | MySQL Tutorial | MySQL Tutorial | 0 |
| 2 | How To Use MySQL | How To Use MySQL | 0 |
| ... |
-- 后缀匹配模式
SELECT id, title, body,
MATCH (title) AGAINST ('*data' IN BOOLEAN MODE) AS score
FROM articles ORDER BY score DESC;
| id | title | body | score |
|---|---|---|---|
| 1 | MySQL Tutorial | MySQL Tutorial | 0 |
| 2 | How To Use MySQL | How To Use MySQL | 0 |
| ... | |||
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 0 |
我们看到前缀模式可以命中,但是后缀模式不可以,所以倒排索引也符合最左匹配原则。
对中文的支持能力
接下来我们看看中文的情况,我们建表的时候给title和body创建了不同的索引。我们分别看看两个索引对中文的响应情况
SELECT id, title, body,
MATCH(title) AGAINST('钟薛高' IN BOOLEAN MODE) AS score_title_b,
MATCH(body) AGAINST('钟薛高' IN BOOLEAN MODE) AS score_body_b
FROM articles;
| id | title | body | score_title_b | score_body_b |
|---|---|---|---|---|
| ... | ||||
| 9 | indexdata full tokenized | indexdata full tokenized | 0 | 0 |
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 | 1.0962 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 1.0844 | 1.0962 |
我们发现在title这个字段搜索“钟薛高”,无法命中id=10这条记录,但是可以命中11这条,原因就是title用的是适配英文的空格分词器,id=11这条做了空格分词,因此可以命中,id=10这条就没有办法命中了。
但是我们看body这个字段却都可以被命中,这就引出了我们的ngram分词器。
不同的分词器
默认的英文分词器是基于空格和停止词的分词方法,对中文这种没有空格的语言就难搞。
ngram是一种适合中文的分词算法,他也是一种比较无脑的机械分词法。原理是,设置一个词条长度的区间,比如n=2,3,4 时,可以拆出所有这个长度的子串而不考虑语义,对应“钟薛高及其创始人林盛被限消”这句话,他可以分出下面这些词:
n=2:钟薛,薛高,高及,及其,其创,创始,始人,人林,林盛,盛被,被限,限消
n=3:钟薛高,薛高及,高及其,及其创,其创始,创始人,始人林,人林盛,林盛被,盛被限,被限消
n=4:钟薛高及,薛高及其,高及其创,及其创始,其创始人,创始人林,始人林盛,人林盛被,林盛被限,盛被限消
所以对ngram的索引来说,这些词都可以被命中,比如我们测试一下“始人林”这个词。
SELECT id, title, body,
MATCH(title) AGAINST('始人林' IN BOOLEAN MODE) AS score_title_b,
MATCH(body) AGAINST('始人林' IN BOOLEAN MODE) AS score_body_b
FROM articles;
| id | title | body | score_title_b | score_body_b |
|---|---|---|---|---|
| ... | ||||
| 9 | indexdata full tokenized | indexdata full tokenized | 0 | 0 |
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 | 1.6326 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 0 | 0 |
我们看到,只有id=10的记录被命中。id=11的记录因为中间有个空格,没有分出“始人林”这个词。
这似乎是中文场景的一个比较好的解决方案,可以确保任意一个单词都被分到。但是,凡事有一利必生一弊,这样检索命中率的确被提高了,同时因为分出了太多的词,会导致索引的空间效率底下。
不同的查询模式
前面的测试都是基于IN BOOLEAN MODE 模式,MySQL还提供了一种模式IN NATURAL LANGUAGE MODE ,我们先对比一下效果。
SELECT id, title, body,
MATCH(title) AGAINST('钟薛高创始人' IN BOOLEAN MODE) AS score_title_b,
MATCH(body) AGAINST('钟薛高创始人' IN BOOLEAN MODE) AS score_body_b,
MATCH(title) AGAINST('钟薛高创始人' IN NATURAL LANGUAGE MODE) AS score_title,
MATCH(body) AGAINST('钟薛高创始人' IN NATURAL LANGUAGE MODE) AS score_body
FROM articles;
| id | title | body | score_title_b | score_body_b | score_title | score_body |
|---|---|---|---|---|---|---|
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 | 0 | 0 | 2.1925 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 0 | 0 | 0 | 2.1925 |
我们发现对于这个查询条件“钟薛高创始人”,因为原文在中间还有“及其”两个字,导致布尔模式无法命中,但是自然语言模式却可以。自然语言模式会把检索条件再做分词去查询,因此上面的例子中“钟薛高创始人”也会做一次ngram分词,然后把所有的词作为搜索条件。
中文的另一种解决方案
前面说到ngram会产生过于冗余的分词,导致索引的空间效率低下。而MySQL的生态又不像elasticsearch那样有良好的中文分词插件,那么如何更近一步提升搜索的精准度,并且具有更好的空间占用情况呢。
答案就在样例数据的id=11这条,我们可以在内容入库之前就做好分词。对于java, python这些高级语言来说,集成一个强大的分词lib易如反掌。下面是一个可行方案的简要实现流程:
- 为需要索引的数据表增加一个搜索关键词字段,并建立默认全文索引(空格分隔)
- 在内容入库的同时把所有需要被检索的字段做好分词,以空格分隔的形式写入搜索关键词字段。
- 搜索的时候用同一个分词方法对搜索条件做分词,用分词结果来创建搜索条件。
类似下面的搜索方式,对搜索条件也做一次预分词即可在 title 索引上得到结果。
SELECT id, title, body,
MATCH(title) AGAINST('钟薛高 创始人' IN BOOLEAN MODE) AS score
FROM articles;
| id | title | body | score |
|---|---|---|---|
| 10 | 钟薛高及其创始人林盛被限消 | 钟薛高及其创始人林盛被限消 | 0 |
| 11 | 钟薛高 及其 创始人 林盛 被 限消 | 钟薛高 及其 创始人 林盛 被 限消 | 2.1689 |
这看起来似乎有一点奇技淫巧的味道,事实上这是顶级搜索引擎谷歌也在使用的解决方案。熟悉 SEO 的朋友一定不会对 TKD 陌生,TKD 分别是:Title(标题),Keywords(关键词),Description(描述/摘要)的英文首字母。我们随便截一张网易新闻的源码图看看:

在keywords 和 description 属性中,都使用了特定分隔符的关键词列表,TKD 在搜索引擎中也是作为高优先级处理的内容。与我们上面提到的预分词方案有异曲同工之妙。
- python 中文分词器——结巴分词https://github.com/fxsjy/jieba
- java 中文分词器——结巴 java 版https://github.com/huaban/jieba-analysis
针对中文的参数调优
下面这三组参数都是用来定义分词 token的长度的。
// for InnoDB
innodb_ft_min_token_size
innodb_ft_max_token_size
// for MyISAM
ft_min_word_len
ft_max_word_len
// for ngram parser
ngram_token_size
前面两组包含 max 和 min的,表示最大和最小的分词长度。需要注意的是InnoDB与MyISAM使用了不同的参数名称,但是含义是一样的。因为英文单词中,两个字母及以下的词基本没什么含义,因此默认的innodb_ft_min_token_size是 3。但是对中文场景来说,两个字的单词反而是大多数,甚至在文言文中,每个字单独都有意义,因此在中文场景使用需要修改这里。
比如在前面的id=11的这条数据,我们搜索“创始人”这个词的时候是可以命中的,但是搜索“限消”就无法命中。原因就是默认的innodb_ft_min_token_size=3,字符数大于等于 3 的才会被索引。
ngram_token_size单纯针对 ngram 分词器设置分词长度,而且不存在最大和最小的设置。
这些参数都不支持热更新,建议使用下面的配置文件的方式修改:
[mysqld]
innodb_ft_min_token_size=2
ft_min_word_len=2
ngram_token_size=2需要注意的是这个配置项的生效需要重启服务。
后记
MySQL做全文索引在性能方面完全没有问题,但是功能方面来说肯定无法做到与专业搜索引擎匹敌。但是胜在方便快捷,MySQL在业务系统的应用非常普遍,同时对于简单的搜索场景来说,如果能满足需求,则没有必要再多维护一套依赖服务。
但是同样有一例必生一弊,全文索引一定会大幅影响表的写入性能,我暂时没有测试是否存在全文索引对 TPS 的影响。我给一张 400 万数据的大表创建索引的时间超过了 1 个小时,其实这个时间未必算慢,因为你要把数据同步进 ES 也不会比这个时间快,但是 MySQL 是一个以事务处理为主的数据库,因此在引入全文索引的时候,也要重点评估 TPS 的峰值能力。
同时也希望中文开发者大牛可以为中文圈贡献一套更强大友好的MySQL内置分词插件。
参考文献
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html